1. Softmax 求导
softmax层输出为 🌊
ajL=∑kexp(zkL)exp(zjL)
其中zjL表示第L层第j个神经元的输入,ajL表示第L层第j个神经元的输出,求ajL对zjL的导数
如果j=i,
∂zi∂aj=∂zi∂(∑kexp(zk)exp(zj))=(∑kexp(zk))2exp(zi)∑kexp(zk)−exp(zi)exp(zj)=aj−aj2=aj(1−aj)
如果j=i
|
声学得分 |
语言模型 |
| “北京便宜坊大鸭梨烤鸭店” |
0.357 |
0.622 |
| “也许是新的” |
0.2222 |
0.532 |
∂zi∂aj=∂zi∂(∑kexp(zk)exp(zj))=∑kexp(zk)−exp(zj)exp(zi)=−ajai
2. cross-entropy求导
loss function为l=−∑kyklogak
对softmax层的输入zj求导,如下
zjl=∂zj∂(−k∑yklogak)=−k∑ykak1∂zj∂ak=−yj.aj1.aj.(1−aj)−k=j∑yk.ak1.∂zj∂ak=−yj+yjaj+k=j∑ykaj=−yj+ajk∑yk=aj−yj
3. label smoothing
对于ground truth为one-hot的情况,使用模型去拟合这样的函数有两个问题,首先是无法保证模型的泛化能力,容易导致过拟合;其次全概率和零概率将鼓励所属类别和非所属类别之间的差距被尽可能的拉大,因为模型太过相信自己的预测。(overconfidence)这时模型认为判断正确的输出在反向传播时没有影响。
为解决这一问题,使得模型没那么肯定,提出了label smoothing。
原ground truth为y(k∣x)=δk,y,添加一个与样本分布无关的分布u(k),得到
y′(k∣x)=(1−ϵ)δk,y+ϵu(k)
用y^(k∣x)表示预测结果,则loss function为
l(y′,y^)=−k=1∑Ky′(k)logy^(k)=(1−ϵ)l(y,y^)+ϵl(u,y^)
label smoothing出自论文《Rethinking the Inception Architechture for Computer Vision》,label smoothing使交叉熵增大,降低overconfidence带来的影响。
Seq-to-Seq中Coverage详解
最早出现在NMT中,在ASR应用中引入语言模型时会导致转写结果不完整(如homophone同音异形词情况,容易导致在decoding过程beam-search中剪枝过程忽略正确答案),引入coverage可以有效缓解
出自ACL2017一篇文章Get To The Point: Summarization with Pointer-Generator Networks
提出pointer-generator机制,这种pointer softmax相当于加入惩罚项,弥补上述提出的转写结果不完整的不足。
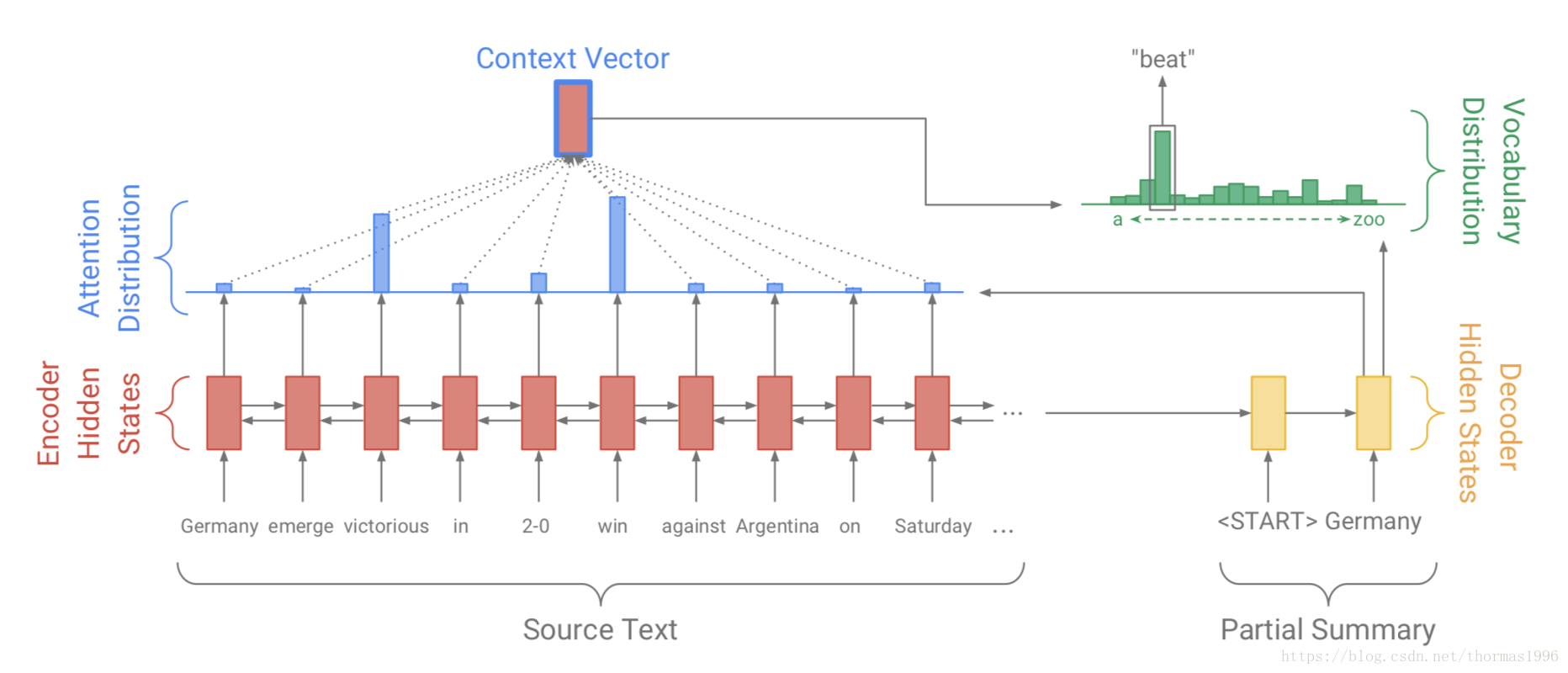
以下是传统Seq2Seq机制框架图
加入coverage后的原理图如下
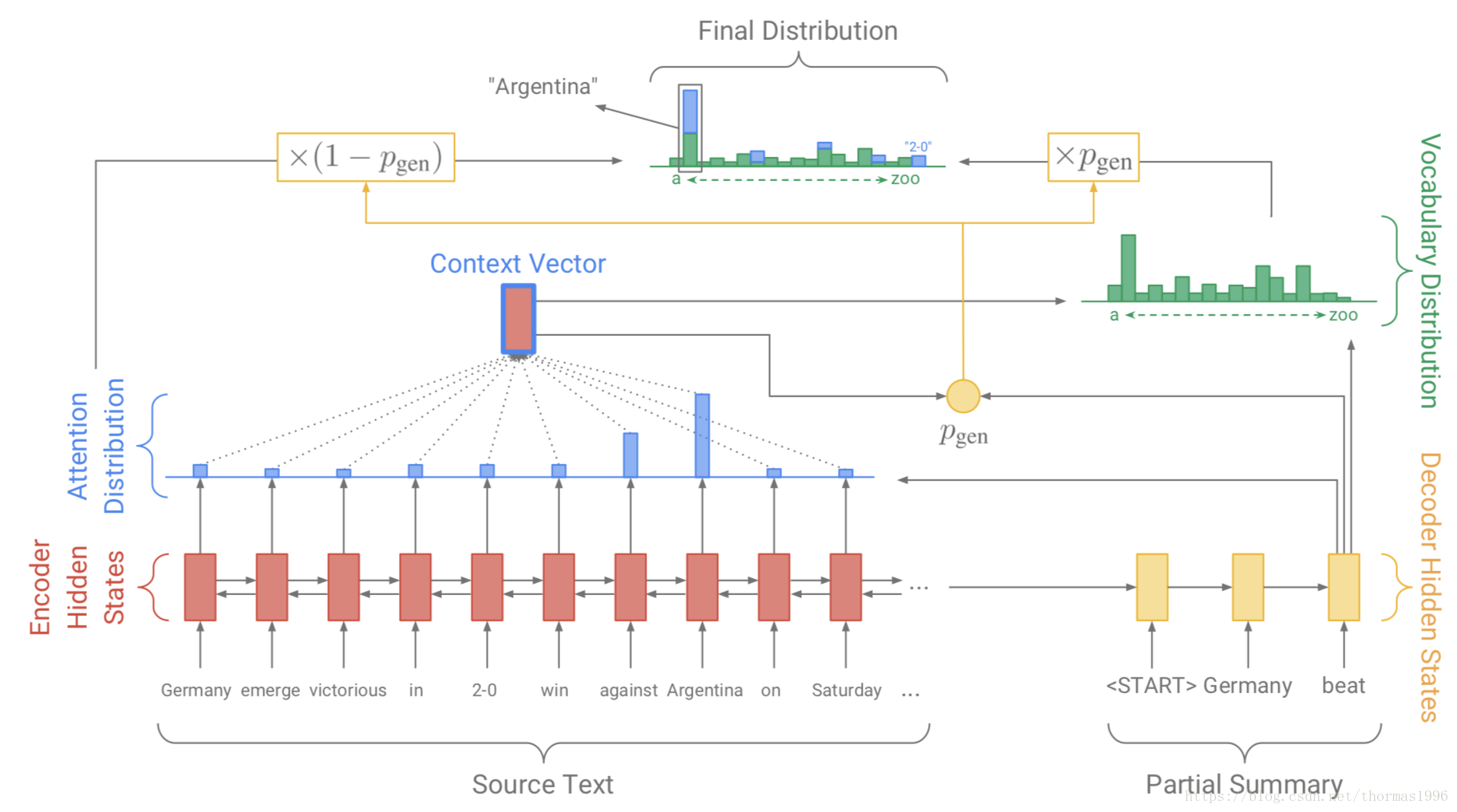
其中pgen是pointer softmax,改动的是attention部分:
eit=vTtanh(Whhi+Wsst+wccit+b)
这里的c不是语义向量,是新定义的一个参数:
ct=t′=1∑t−1at′
是一个长度为输入长度的向量,第一项是之前时刻输入第一个词attention权重的叠加和,以此类推。加这个参数目的是为了给attention之前生成词的信息,如果之前生成过这些词,那么后续要抑制,通过loss函数加惩罚项实现:
loss=−logP(wt∗)+λ∑imin(at,cit)
原理是如果该词之前出现过了,那么它的cit就很大,那么为了减小loss,就需要ait变小(因为loss中一项是取两者最小值),ait小就意味着这个位置被注意的概率减少。
